Todos los lenguajes de programación (o
casi todos) tienen un generador pseudo-aleatorio. Las sintaxis
varían: ran, grand, rand, Random...
Estas son funciones que, según los manuales de usuarios, ``dan
como resultado números al azar''. Lo que se entiende por ``números
al azar'' depende, en principio, del tipo de número (booleanos,
enteros, reales). Convenimos en denotar por Random a la
función que ``da como resultado un
número real al azar en el
intervalo ![]() ''. Esta frase contiene, de hecho, a dos
propiedades distintas, que admitiremos como postulados.
''. Esta frase contiene, de hecho, a dos
propiedades distintas, que admitiremos como postulados.
Postulados.
Interpretación:
En el lenguaje corriente ``al azar'' no significa solamente
aleatorio si no también uniformemente
distribuido. Seleccionar al azar, es dar las mismas oportunidades
a todos los resultados posibles (equiprobabilidad). Lo que se
espera de un número real seleccionado ``al azar'' en ![]() es
que caiga entre
es
que caiga entre ![]() y
y ![]() con probabilidad
con probabilidad ![]() , y esta
probabilidad es la misma de caer entre
, y esta
probabilidad es la misma de caer entre ![]() y
y ![]() . Dos
intervalos incluidos en
. Dos
intervalos incluidos en ![]() tienen la misma probabilidad de
que el número se encuentre en ellos, si tienen la misma longitud,
y esta probabilidad es la longitud de los intervalos. Los
postulados anteriores tienen otra consecuencia. Si se consideran
pares sucesivos de llamadas de la función Random como las
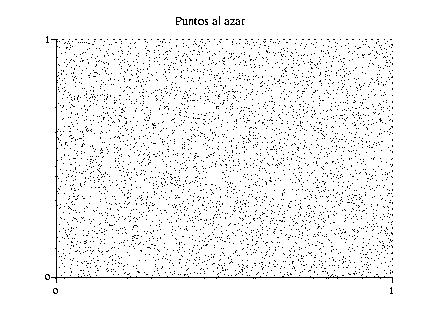
coordenadas de un punto en el plano, estos puntos son ``puntos al
azar'' en
tienen la misma probabilidad de
que el número se encuentre en ellos, si tienen la misma longitud,
y esta probabilidad es la longitud de los intervalos. Los
postulados anteriores tienen otra consecuencia. Si se consideran
pares sucesivos de llamadas de la función Random como las
coordenadas de un punto en el plano, estos puntos son ``puntos al
azar'' en ![]() (ver la figura 1). El significado
preciso es que estos puntos son independientes y además:
(ver la figura 1). El significado
preciso es que estos puntos son independientes y además:
La probabilidad de que un punto, cuyas coordenadas son obtenidas a
partir de la función Random, caiga en un cierto rectángulo
es igual a la superficie del rectángulo. Esto puede,
evidentemente, extenderse a cualquier dimensión. Tríos de llamadas
sucesivas de
Random, son las coordenadas de ``puntos al
azar'' en el cubo ![]() , etc...
, etc...
La probabilidad de que Random dé un valor específico es nula:
Al admitir a la vez que Random puede tomar un número
infinito de valores diferentes y que la probabilidad de tomar un
valor especifico es nula, tenemos una paradoja. Veremos en
situaciones prácticas que la situación es ligeramente diferente,
sin que por ello nos cuestionemos los postulados de la definición
de Random.
Una vez aceptados los dos postulados, todo análisis de algoritmo
que contiene a Random, es una demostración matemática tan
rigurosa como otra.
Ejemplo 1: Lanzamiento del dado.
Para todo
![]() ,
,
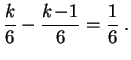 |
No hay que deducir de este ejemplo que Int
![]() Random
Random![]() es la mejor forma de obtener un
entero al azar
entre
0 y
es la mejor forma de obtener un
entero al azar
entre
0 y ![]() . Los generadores de números aleatorios usuales
permiten tener tipos diferentes de números como resultado: números
reales distribuidos uniformemente en el intervalo
. Los generadores de números aleatorios usuales
permiten tener tipos diferentes de números como resultado: números
reales distribuidos uniformemente en el intervalo ![]() ,
booleanos, enteros y aún complejos.
,
booleanos, enteros y aún complejos.
Ejemplo 2:
(Int
![]() denota la parte entera).
denota la parte entera).
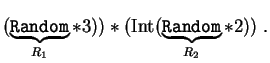
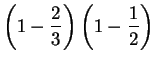 |
|||
Se demuestra igualmente que
![]() y
y
![]() .
.
Observación: Contrario a las
apariencias, el algoritmo anterior no da valores entre ![]() y
y ![]() .
Teóricamente, la probabilidad de que Random dé el valor
.
Teóricamente, la probabilidad de que Random dé el valor ![]() es nula. En la práctica, los generadores están, en general, hechos
de manera tal que nunca dan ni 0 ni
es nula. En la práctica, los generadores están, en general, hechos
de manera tal que nunca dan ni 0 ni ![]() .
.
Los
generadores aleatorios permiten simular sucesiones de experimentos
aleatorios independientes y por tanto podemos calcular, de forma
aproximada, probabilidades aplicando la
Ley de los Grandes
Números. El algoritmo genérico de cálculo de una
frecuencia
experimental tomará la siguiente forma.
![]()
Repetir ![]() veces
veces
experimento
Si (![]() se realiza) entonces
se realiza) entonces
![]()
finSi
finRepetir
![]()
La variable ![]() es la
frecuencia experimental del evento
es la
frecuencia experimental del evento ![]() en
los
en
los ![]() experimentos.
experimentos.
Ejemplo : El experimento es lanzar un
dado. El evento ![]() es: ``El resultado es al menos igual a
es: ``El resultado es al menos igual a ![]() ''.
''.
![]()
Repetir ![]() veces
veces
![]() Int
Int![]() Random
Random![]() (* lanzar un dado *)
(* lanzar un dado *)
Si (![]() ) entonces
) entonces
![]()
finSi
finRepetir
![]()
Al salir de este algoritmo, ![]() contiene un número que estará
más cerca de
contiene un número que estará
más cerca de ![]() en dependencia de cuan grande es el valor de
en dependencia de cuan grande es el valor de
![]() que se toma. Mientras mayor sea el número de experimentos, más
preciso es el resultado.
que se toma. Mientras mayor sea el número de experimentos, más
preciso es el resultado.