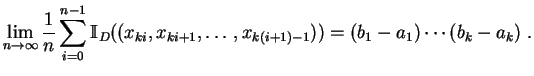
Al observar una sucesión de números reales, dada por un generador aleatorio específico, ¿cómo decidir si este generador es adecuado? La única forma práctica de estimar una probabilidad es expresarla como un límite de frecuencias experimentales.
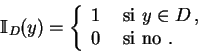
El vector
![]() es la
es la
![]() -ésima
-ésima ![]() -tupla de elementos consecutivos de la sucesión. la
suma
-tupla de elementos consecutivos de la sucesión. la
suma
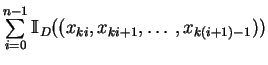 es el número de
es el número de ![]() -tuplas de elementos consecutivos
de la sucesión que están en
-tuplas de elementos consecutivos
de la sucesión que están en ![]() , entre los
, entre los ![]() primeros.
primeros.
Por tanto, la definición anterior dice que entre las ![]() -tuplas de
elementos consecutivos de elementos de la sucesión, la proporción
de los que caen en un rectángulo dado debe tender al volumen de
ese rectángulo (en dimensión
-tuplas de
elementos consecutivos de elementos de la sucesión, la proporción
de los que caen en un rectángulo dado debe tender al volumen de
ese rectángulo (en dimensión ![]() ). Esta definición es pasablemente
utópica. En particular ella conlleva a que la probabilidad de que
Random caiga en un punto prefijado es nula. Sabiendo que
sólo hay una cantidad numerable de números racionales en
). Esta definición es pasablemente
utópica. En particular ella conlleva a que la probabilidad de que
Random caiga en un punto prefijado es nula. Sabiendo que
sólo hay una cantidad numerable de números racionales en ![]() ,
la probabilidad de caer sobre un número racional es de también
nula. Pero la computadora conoce solamente los números decimales,
y aún más un número finito de ellos, por tanto la función
Random
no puede dar como resultado otra cosa que números
racionales. Pero esto no es un inconveniente.
Si sabemos construir una sucesión
uniforme de dígitos entre 0 y
,
la probabilidad de caer sobre un número racional es de también
nula. Pero la computadora conoce solamente los números decimales,
y aún más un número finito de ellos, por tanto la función
Random
no puede dar como resultado otra cosa que números
racionales. Pero esto no es un inconveniente.
Si sabemos construir una sucesión
uniforme de dígitos entre 0 y ![]() , podremos obtener números
reales al azar en
, podremos obtener números
reales al azar en ![]() , aproximados hasta la
, aproximados hasta la ![]() -ésima posición
decimal, considerando
-ésima posición
decimal, considerando ![]() -tuplas consecutivas de dígitos de la
sucesión original. Este es el principio de las ``tablas de números
aleatorios'' que todavía se encuentran en algunos libros. La misma
observación puede hacerse en base
-tuplas consecutivas de dígitos de la
sucesión original. Este es el principio de las ``tablas de números
aleatorios'' que todavía se encuentran en algunos libros. La misma
observación puede hacerse en base ![]() . Es suficiente saber definir
que cosa es una
sucesión aleatoria de bits. Veamos a continuación
la definición de
. Es suficiente saber definir
que cosa es una
sucesión aleatoria de bits. Veamos a continuación
la definición de ![]() -uniformidad para las sucesiones booleanas 0
o
-uniformidad para las sucesiones booleanas 0
o ![]() ).
).
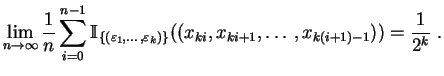
Lo que esperamos de la sucesión de llamadas de Random, es
que la sucesión que se obtiene sea ![]() -uniforme, para todo entero
-uniforme, para todo entero
![]() (decimos
(decimos ![]() -uniforme). Esto es evidentemente ilusorio,
porque el infinito no existe en un ordenador. Lo más que podemos
hacer es verificar que nada inverosímil se produce en la sucesión
finita observada. Precisamente este es el objetivo de los tests
estadísticos, separar lo plausible de lo que es poco verosímil.
Multitud de tests han sido pensados para probar a los generadores
aleatorios.
-uniforme). Esto es evidentemente ilusorio,
porque el infinito no existe en un ordenador. Lo más que podemos
hacer es verificar que nada inverosímil se produce en la sucesión
finita observada. Precisamente este es el objetivo de los tests
estadísticos, separar lo plausible de lo que es poco verosímil.
Multitud de tests han sido pensados para probar a los generadores
aleatorios.
``Definición''
Una ![]() -tupla de números en
-tupla de números en ![]() será llamada pseudo aleatoria
si pasa con éxito una serie de tests estadísticos, cada uno de
ellos con el objetivo de verificar una consecuencia de la
será llamada pseudo aleatoria
si pasa con éxito una serie de tests estadísticos, cada uno de
ellos con el objetivo de verificar una consecuencia de la
![]() -uniformidad. El número de los tests, así como el entero
-uniformidad. El número de los tests, así como el entero
![]() son una función creciente de la exigencia del
usuario.
son una función creciente de la exigencia del
usuario.
Entre las diferentes formalizaciones del azar que pudieron haber
sido propuestas, la noción de sucesión ![]() -uniforme es la
única utilizable en la práctica: ella es la única que podemos
comprobar para un generador dado y ella basta para justificar
todas las aplicaciones de los generadores pseudo-aleatorios. Los
generadores que se suministran con los compiladores más usados
vienen de una larga experimentación estadística, y han sobrevivido
a lo largo del tiempo porque satisfacen las necesidades de
numerosos usuarios, lo que no impide que se mantengan bajo
vigilancia.
-uniforme es la
única utilizable en la práctica: ella es la única que podemos
comprobar para un generador dado y ella basta para justificar
todas las aplicaciones de los generadores pseudo-aleatorios. Los
generadores que se suministran con los compiladores más usados
vienen de una larga experimentación estadística, y han sobrevivido
a lo largo del tiempo porque satisfacen las necesidades de
numerosos usuarios, lo que no impide que se mantengan bajo
vigilancia.
¿Cómo están programados? Aún las sucesiones
recurrentes más simples pueden ser caóticas y por tanto ser
ejemplos de sucesiones aparentemente aleatorias. Y esto, aún el
sentido intuitivo de aleatorio (imposible de prever), está en
contradicción con la definición de una sucesión por recurrencia
(cada término es una función conocida del anterior). Para un
ordenador sólo existe un número finito de valores. Los valores de
Random son calculados siempre a partir de enteros
distribuidos en
![]() donde
donde ![]() es un número
grande (del orden de
es un número
grande (del orden de ![]() al menos para los generadores
usuales). Para dar un número real en
al menos para los generadores
usuales). Para dar un número real en ![]() , basta dividir por
, basta dividir por
![]() . En la práctica sólo puede obtenerse un número finito de
valores, y esto con probabilidad positiva. Esto contradice los
postulados de la definición de Random, pero no constituye un
inconveniente importante en la medida en que
. En la práctica sólo puede obtenerse un número finito de
valores, y esto con probabilidad positiva. Esto contradice los
postulados de la definición de Random, pero no constituye un
inconveniente importante en la medida en que ![]() sea muy grande.
Para obtener otro tipo de valores, por ejemplo números enteros
distribuidos uniformemente en
sea muy grande.
Para obtener otro tipo de valores, por ejemplo números enteros
distribuidos uniformemente en
![]() o números booleanos
(cara o cruz), es inútil pasar por llamadas de Random, es
mejor partir directamente del generador sobre
o números booleanos
(cara o cruz), es inútil pasar por llamadas de Random, es
mejor partir directamente del generador sobre
![]() sin dividir previamente por
sin dividir previamente por ![]() . Esto se
tiene en cuenta en la mayoría de los lenguajes en uso.
. Esto se
tiene en cuenta en la mayoría de los lenguajes en uso.
El valor que nos da un generador es una función del valor
precedente o de varios valores obtenidos con anterioridad. En el
primer caso, la sucesión que se calcula es una sucesión
recurrente. Para comenzar el proceso se selecciona una
``semilla'', ![]() , en el conjunto
, en el conjunto
![]() , los
valores de la sucesión se calculan a partir de una expresión
, los
valores de la sucesión se calculan a partir de una expresión
![]() , donde
, donde ![]() es una función de
es una función de
![]() en si mismo, suficientemente simple como para ser
calculada rápidamente.
en si mismo, suficientemente simple como para ser
calculada rápidamente.
Nos enfrentamos entonces a un problema importante: toda sucesión
recurrente sobre un conjunto finito es periódica. La
sucesión de valores que nos da Random hará, necesariamente,
un lazo. ¿Podemos considerar como aleatoria a una sucesión
periódica? Sí, puede ser, si el período es lo suficientemente
grande en relación con el número de términos que vamos a emplear.
La prudencia debe prevalecer en general, de todas formas hay que
evitar la idea intuitiva de que mientras más complicada sea la
forma de calcular ![]() a partir de
a partir de ![]() , más independientes
serán los valores entre síy el generador será mejor.
Los generadores aleatorios más simples son los
generadores por congruencias. Ellos son de la siguiente forma:
, más independientes
serán los valores entre síy el generador será mejor.
Los generadores aleatorios más simples son los
generadores por congruencias. Ellos son de la siguiente forma:
Resultados diversos en matemáticas, dicen cómo
seleccionar ``correctamente'' ![]() ,
, ![]() y
y ![]() . Ya prácticamente no
se usan, desde que aparecieron nuevos generadores mas eficientes.
El generador que damos a continuación estaba muy difundido y en
general era satisfactorio; todavía puede ser útil.
. Ya prácticamente no
se usan, desde que aparecieron nuevos generadores mas eficientes.
El generador que damos a continuación estaba muy difundido y en
general era satisfactorio; todavía puede ser útil.
Todo generador necesita una inicialización. Para un mismo valor de
la semilla ![]() , se obtiene siempre la misma sucesión de valores
al emplear el generador. Para obtener resultados diferentes de una
sucesión a otra, es necesario cambiar la semilla al principio de
cada calculo. En dependencia del lenguaje que se utilice, esta
inicialización puede dejarse a la elección del usuario, o puede
ser realizada a partir del contador de tiempo del
ordenador(función randomize en Pascal, seed en
C...). La instrucción de tomar una semilla aleatoria debe
figurar una sola vez, al principio del programa principal.
, se obtiene siempre la misma sucesión de valores
al emplear el generador. Para obtener resultados diferentes de una
sucesión a otra, es necesario cambiar la semilla al principio de
cada calculo. En dependencia del lenguaje que se utilice, esta
inicialización puede dejarse a la elección del usuario, o puede
ser realizada a partir del contador de tiempo del
ordenador(función randomize en Pascal, seed en
C...). La instrucción de tomar una semilla aleatoria debe
figurar una sola vez, al principio del programa principal.